Computer Vision Development
Custom-built deep learning models that see, understand, and act on visual data — trained on your specific industry and deployed where you need them.
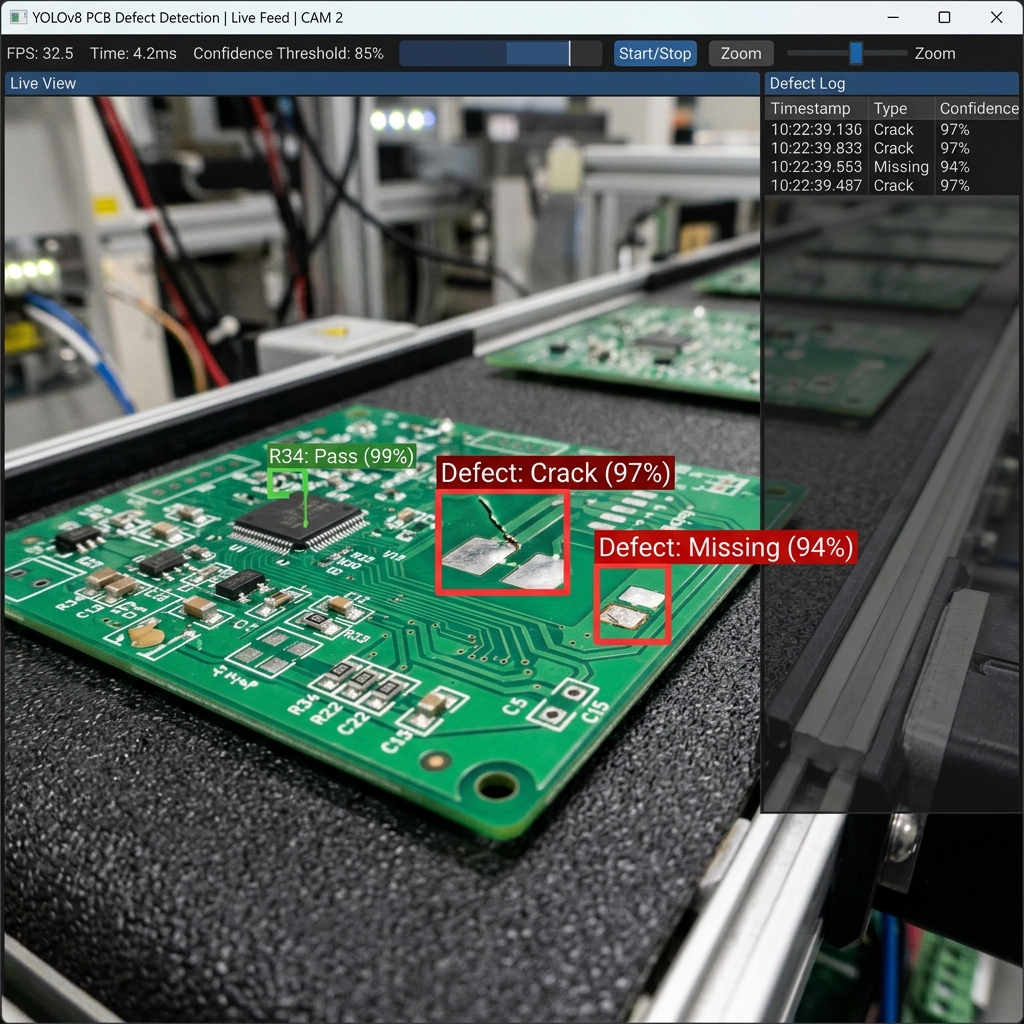
Custom Computer Vision Development
Computer vision is the branch of artificial intelligence that enables machines to interpret and understand visual information from the world — photographs, video streams, thermal imagery, and more. At CloudZigs, we design and build production-grade computer vision systems from the ground up, tailored to your specific operational requirements rather than forcing generic, off-the-shelf models onto your unique challenges.
From dataset collection and annotation through model architecture selection, training, validation, and deployment — our end-to-end development process ensures that every computer vision solution we deliver is accurate, robust, and optimised for your deployment environment, whether that is a cloud server, an on-premise GPU node, or a compact edge device with limited compute resources.
Our engineering team has built and deployed models spanning object detection (YOLO, Faster R-CNN, DETR), image classification (ResNet, EfficientNet, ViT), semantic segmentation, pose estimation, anomaly detection, optical character recognition (OCR), and multi-camera tracking systems. We have deployed solutions serving retail chains, poultry farms, warehouses, hospitals, and smart cities across India.
Core Capabilities
Object Detection & Tracking
Detect and track multiple objects simultaneously in real-time video streams — people, vehicles, products, animals, or custom objects — with bounding box precision and unique ID assignment across frames.
Image Classification
Classify images into custom categories with high accuracy. Ideal for quality control, defect detection, product identification, disease spotting in agriculture, and document processing.
Semantic Segmentation
Pixel-level understanding of scenes — identify and delineate every region of interest in an image. Used for medical imaging, satellite analysis, autonomous navigation, and manufacturing inspection.
Pose Estimation
Detect human body key-points and posture in real time. Applied for workplace ergonomics monitoring, sports performance analysis, rehabilitation tracking, and safety compliance.
Anomaly Detection
Train models to learn "normal" visual patterns and automatically flag deviations — product defects on manufacturing lines, unusual animal behaviour on farms, or suspicious patterns in surveillance feeds.
OCR & Document AI
Extract structured text from images, invoices, license plates, ID cards, and forms. Automate data entry workflows, vehicle access logs, and compliance documentation at scale.
Our Technology Stack
We work with the leading frameworks and platforms in computer vision and deep learning, ensuring your solution uses proven, industry-standard technology:
PyTorchTensorFlowOpenCVUltralytics YOLODetectron2MMDetectionHugging Face
YOLOv8 / YOLOv9RT-DETREfficientDetSAM (Segment Anything)Vision TransformerResNet / EfficientNet
NVIDIA TensorRTONNX RuntimeOpenVINOAWS / Azure / GCPJetson Nano / AGXRaspberry Pi
Industry Applications
Agriculture & Poultry Farming
Dead bird detection, disease classification from visual symptoms, bird counting, feed/water level monitoring, egg production tracking, and flock behaviour analysis using overhead cameras.
Manufacturing & Quality Control
Inline defect detection on production lines at full production speed, surface scratch detection, dimension verification, component presence/absence checks, and label inspection.
Healthcare & Medical Imaging
AI-assisted radiology for lesion detection, tumour segmentation in CT/MRI scans, wound assessment, medication dispensing error detection, and patient fall prevention in hospitals.
Smart Transportation
Licence plate recognition for parking management, traffic flow counting, pothole detection on roadways, vehicle classification, and driver drowsiness detection systems.
Our Development Process
Discovery & Requirements
We analyse your operational challenges, existing camera/data infrastructure, performance requirements, and deployment constraints to define the precise scope of the CV solution.
Data Collection & Annotation
We collect diverse, representative training data from your environment and annotate it with bounding boxes, polygons, or masks. We also leverage data augmentation and transfer learning to reduce data requirements.
Model Training & Validation
We train, fine-tune, and validate models against held-out test sets, iterating on architecture, hyperparameters, and augmentation strategies until target accuracy metrics are consistently achieved.
Optimisation & Deployment
Models are quantised, pruned, and exported to optimised runtimes (TensorRT, ONNX, OpenVINO) for maximum inference speed on your target hardware — cloud GPU, edge device, or mobile.
Integration & Ongoing Support
We integrate the vision pipeline into your existing applications via REST API, gRPC, or MQTT streams, and provide ongoing model retraining services as your operational environment evolves.
Frequently Asked Questions
Start Your CV Project
Tell us your use case and we'll scope a custom computer vision solution for you.
Book a Free ConsultationWhat We Deliver
- Custom model training & fine-tuning
- Dataset collection & annotation
- Edge & cloud deployment
- REST API / gRPC integration
- Real-time video pipeline
- Model optimisation (TensorRT)
- Full source code ownership
- Ongoing retraining support
Related Services
Have a Vision Problem? We'll Build the AI to Solve It.
From concept to production-grade deployment, CloudZigs engineers custom computer vision solutions that deliver measurable business impact. Let's discuss your use case today.